内容进一步完善,提供了示例JSON
This commit is contained in:
@@ -37,7 +37,6 @@ modules下的datax-admin下的conf下的bootstrap.properties
|
||||
2.注意datax-executor下的bin下的env.properties的PYTOHON_PATH的配置地址,需与我们安装的datax目录一致
|
||||

|
||||
|
||||
|
||||
六、启动datax-web及访问
|
||||
执行datax-web-2.1.2下的bin下的start-all.sh启动所有模块
|
||||

|
||||
@@ -75,9 +74,35 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
|
||||
**(三) 实际应用**
|
||||
如下为实际应用示例
|
||||
3.1 任务管理配置截图
|
||||
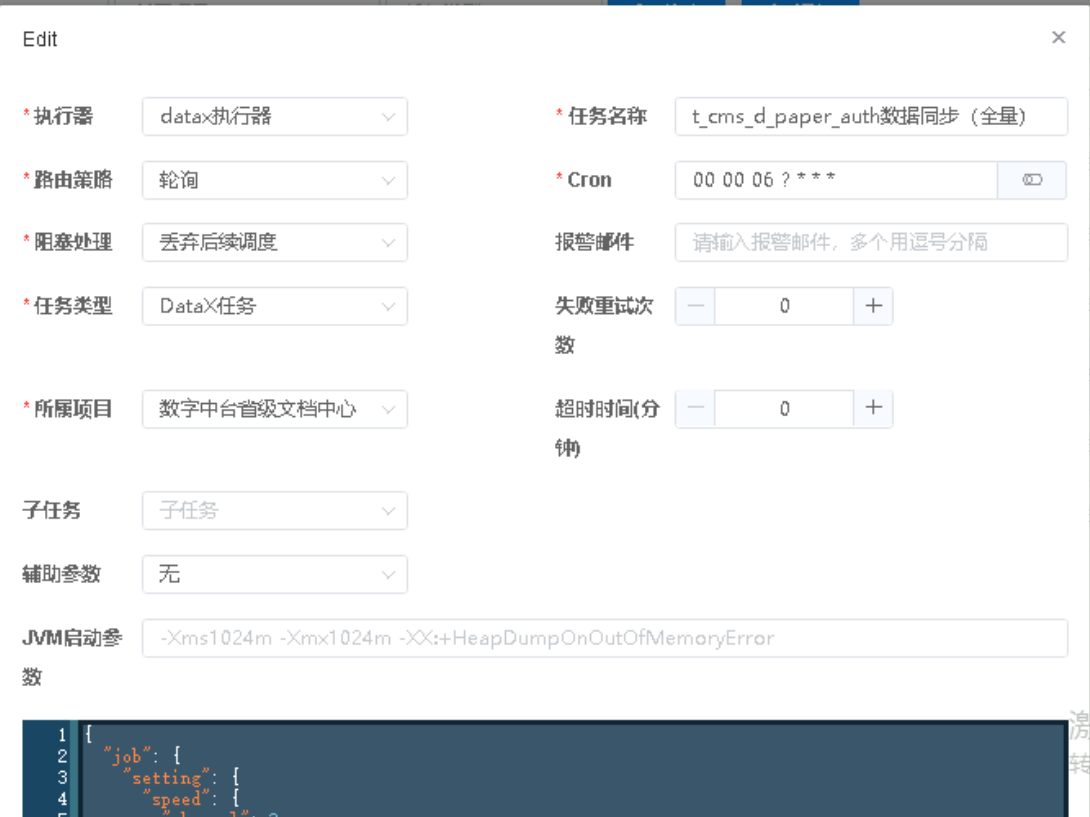
|
||||
3.2 全量数据同步json配置【注意:同步数据前,会删除目标表的全部数据】
|
||||
3.1 如何新增任务
|
||||
第1步首先进行任务构建,获取datax同步任务脚本,选择任务构建配置数据读取源信息。
|
||||
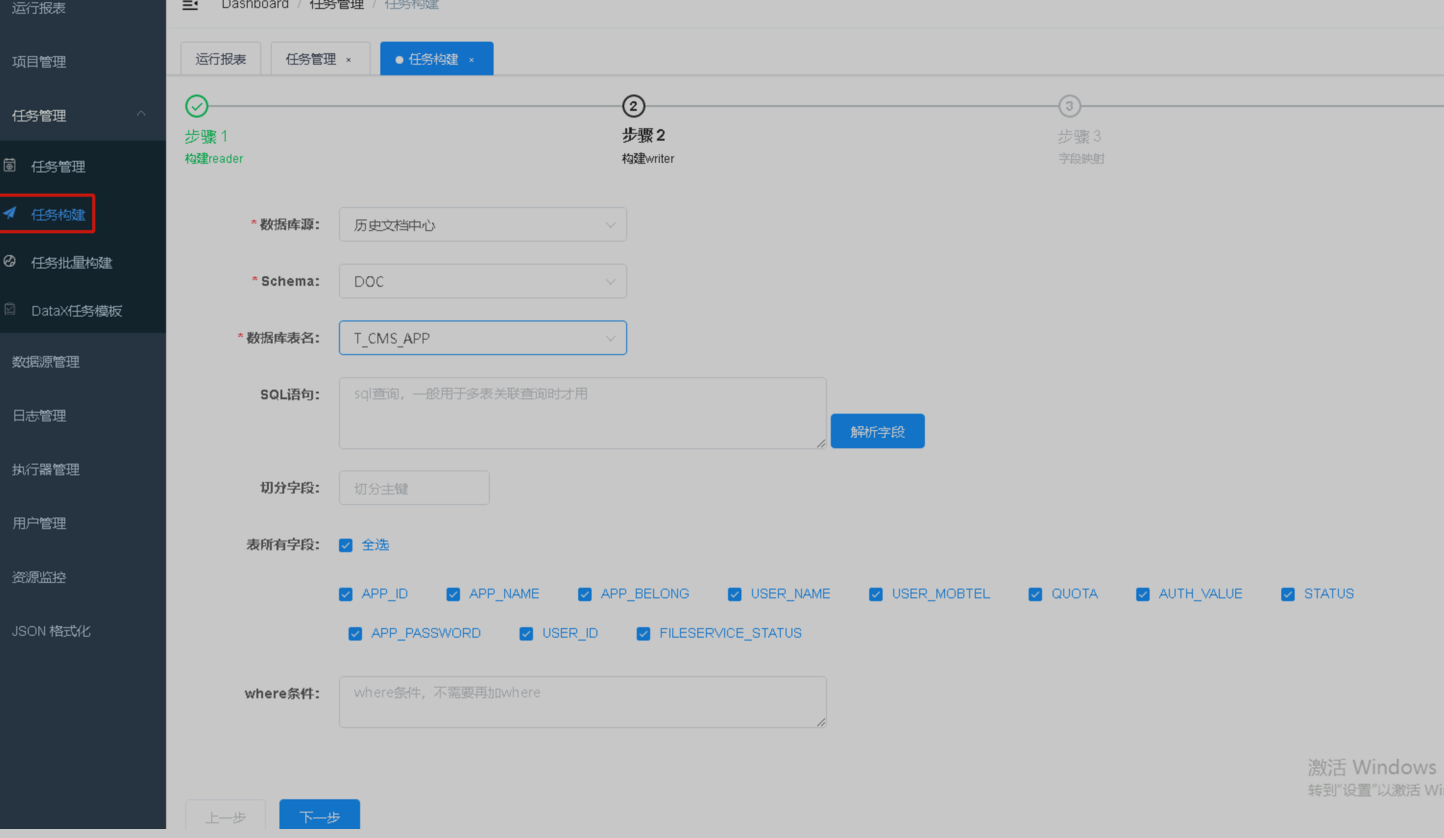
|
||||
|
||||
|
||||
第2步配置数据写入源,前置sql语句代表执行同步前会执行的sql,例如全量同步前,对数据库清空,则在前置sql写入删除全表数据语句。
|
||||
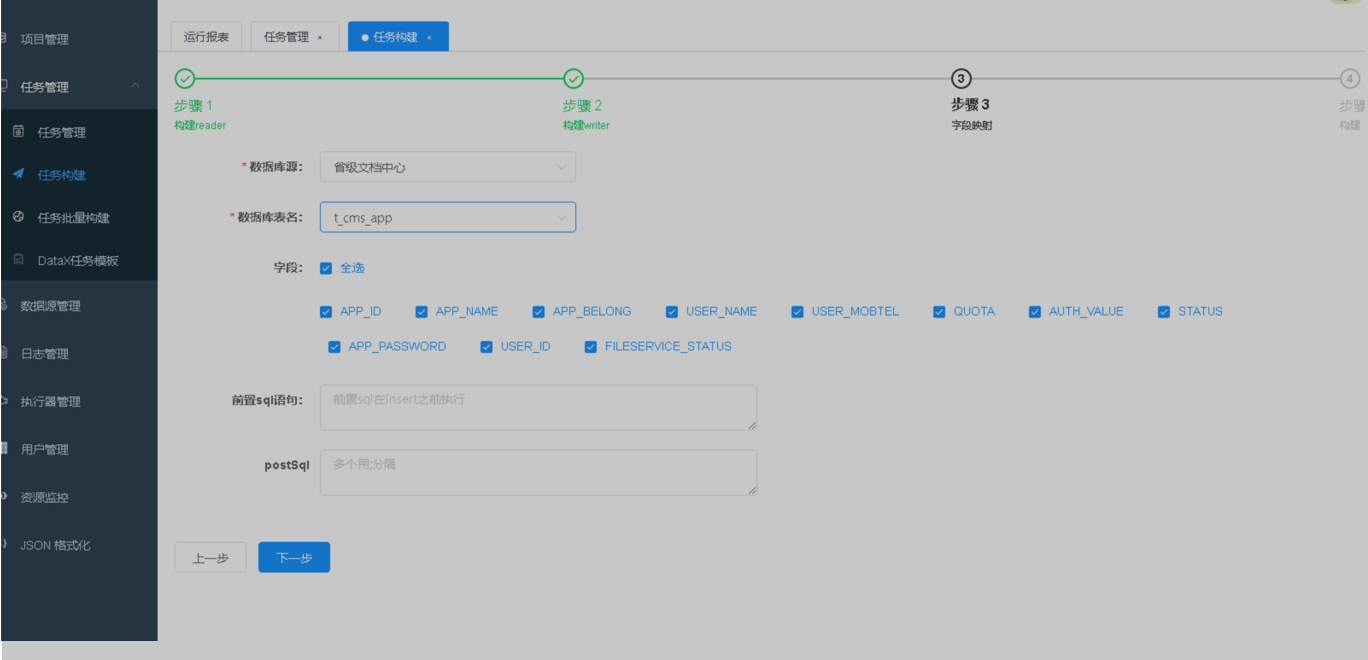
|
||||
|
||||
第3步 选择同步表的字段映射,比对字段数量与字段是否一致。
|
||||
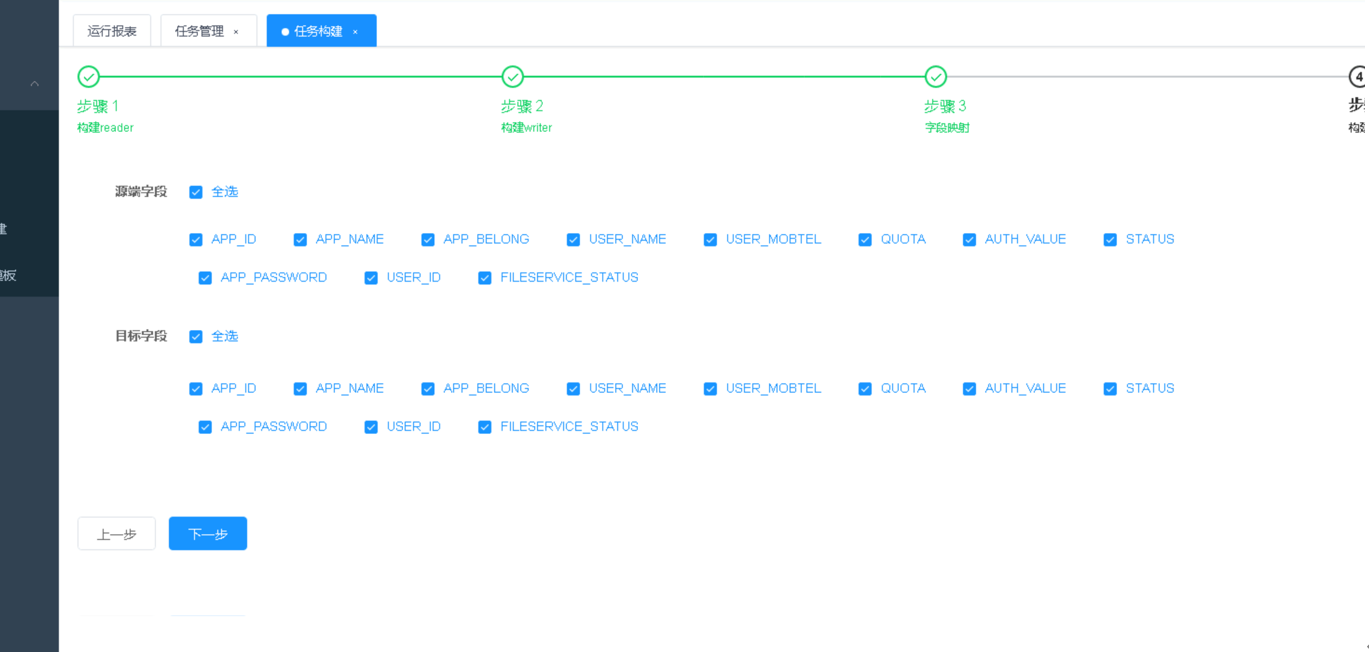
|
||||
|
||||
第4步点击【构建】生成datax同步任务脚本,点击【复制json】后进入任务管理。
|
||||
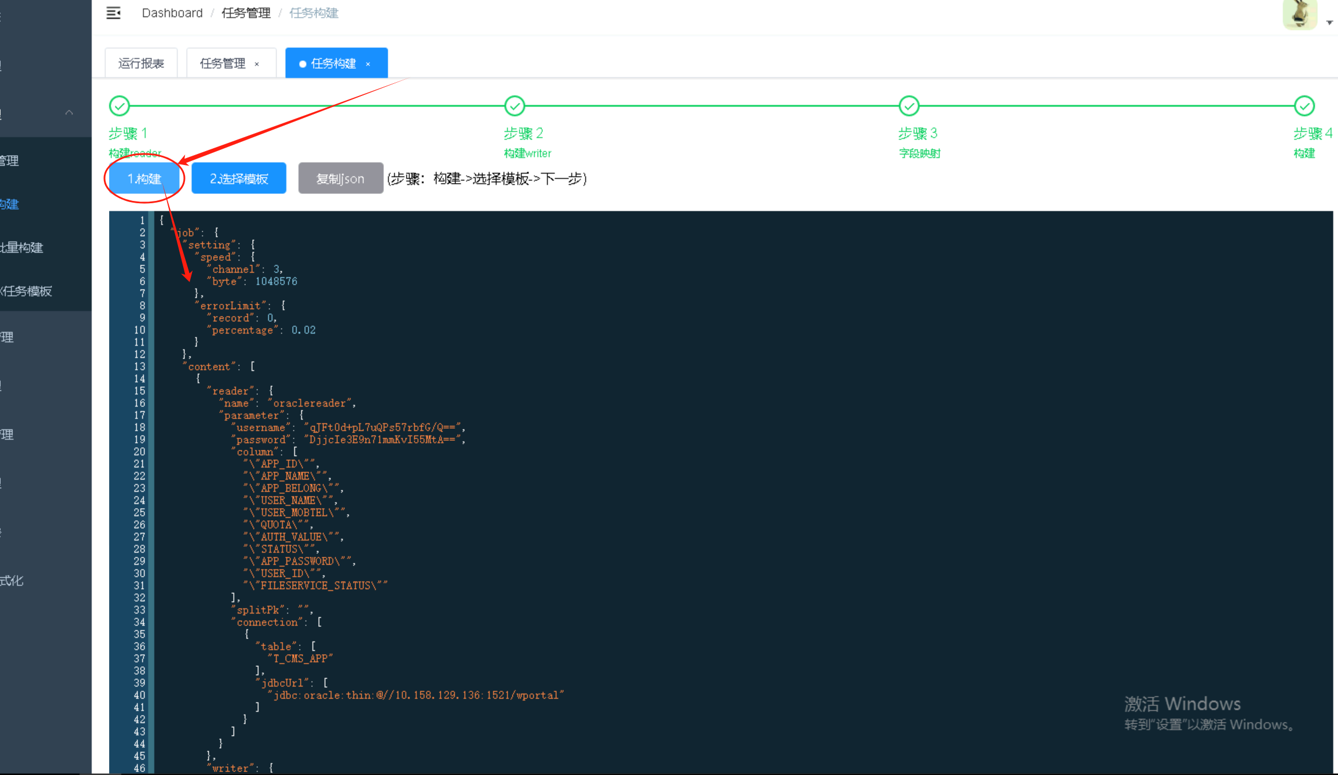
|
||||
|
||||
第5步进入任务管理,新增任务,执行器选择【datax执行器】,路由策略选择【轮询】,阻塞策略选择【丢弃后续调度】,任务类型选择【DataX任务】,将复制的datax任务脚本粘贴在下方的代码框内,选择所属项目,输入任务名称和配置定时触发表达式点击【确定】则完成任务的创建。
|
||||
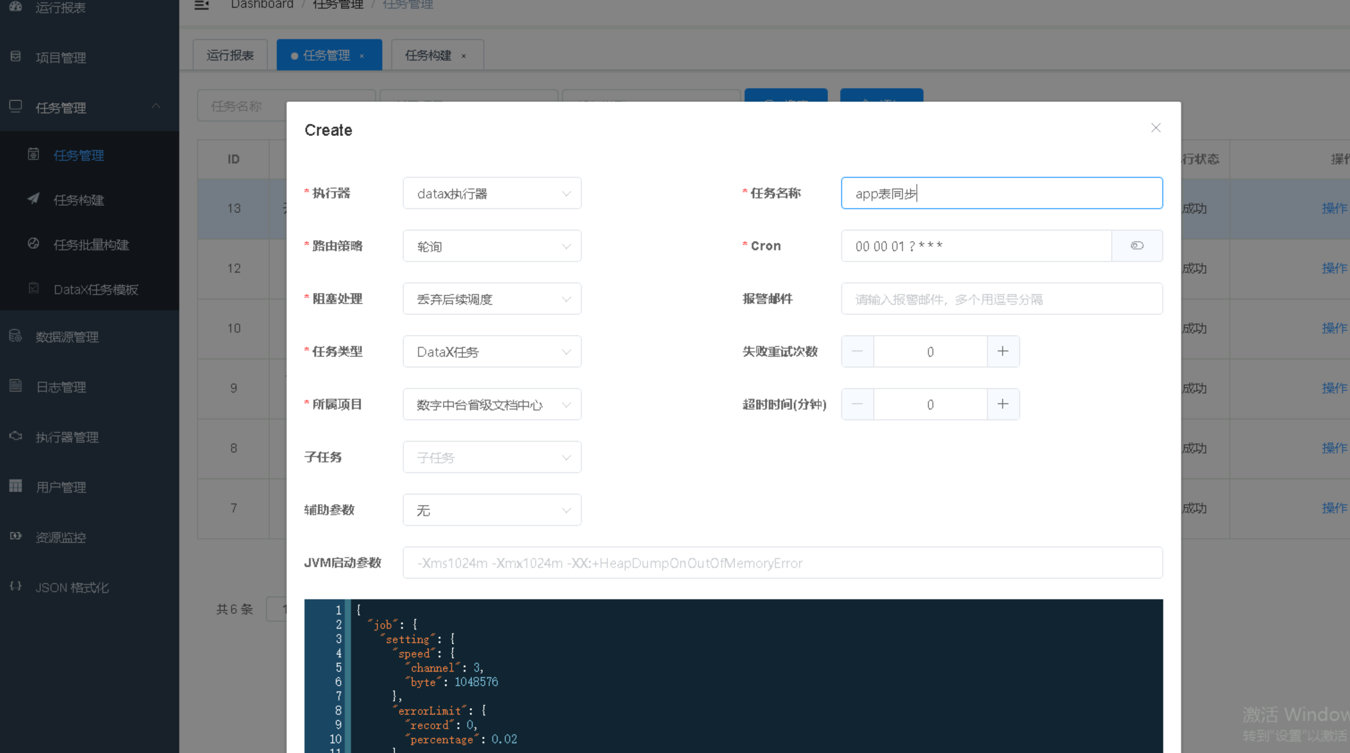
|
||||
|
||||
第6步任务创建完后,默认不会启动,需要点击按钮开关进行任务的启动,启动前可手动执行一次确认任务触发的逻辑和内容无误,再开启定时调度。
|
||||
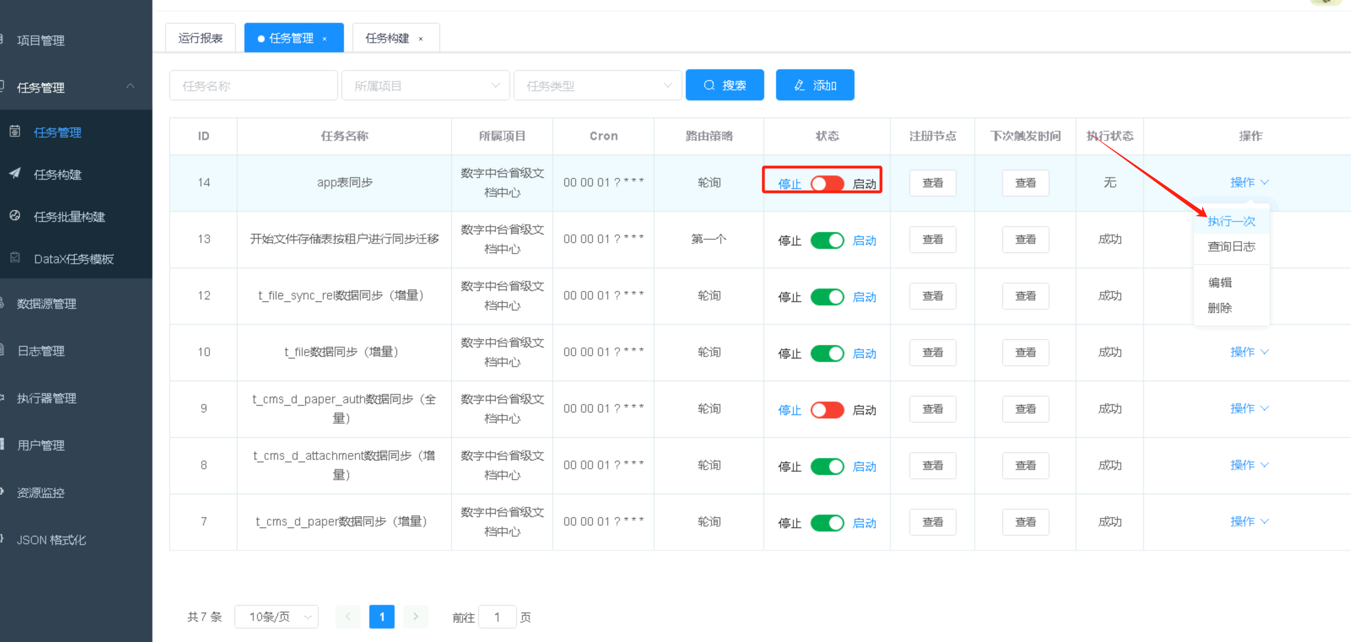
|
||||
|
||||
注意事项:以上创建的任务为全量同步模式,且如果目标表没进行数据清空,会存在主键冲突脏数据报错,需要调整脚本写入模式为update,这样同步会对重复数据按主键进行更新,前提为同步的表必须存在主键字段。
|
||||
|
||||
3.2 如何增量同步数据
|
||||
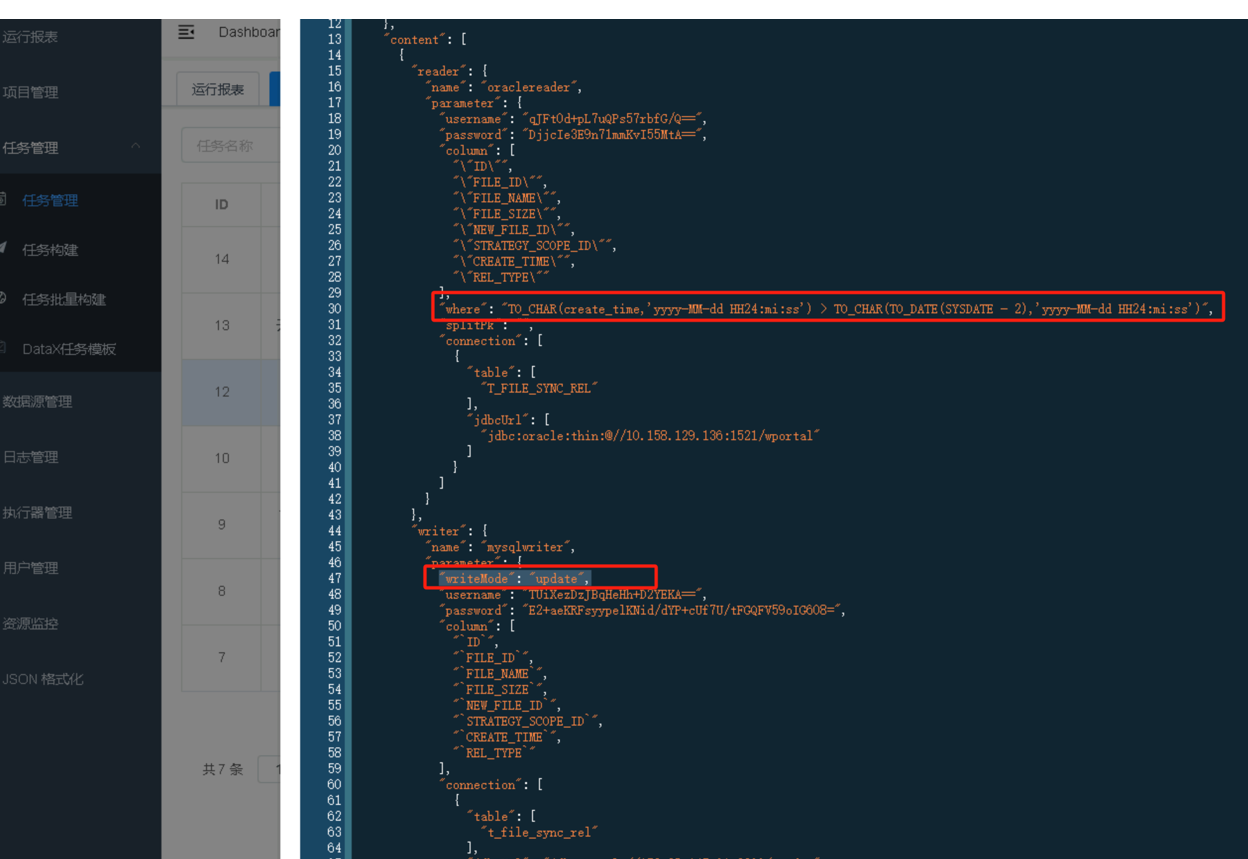
在任务构建时,配置where条件,筛选条件内的数据,例如筛选2天内数据进行同步迁移(注意事项:需保证写入源的写入模式是update,"writeMode": "update")
|
||||
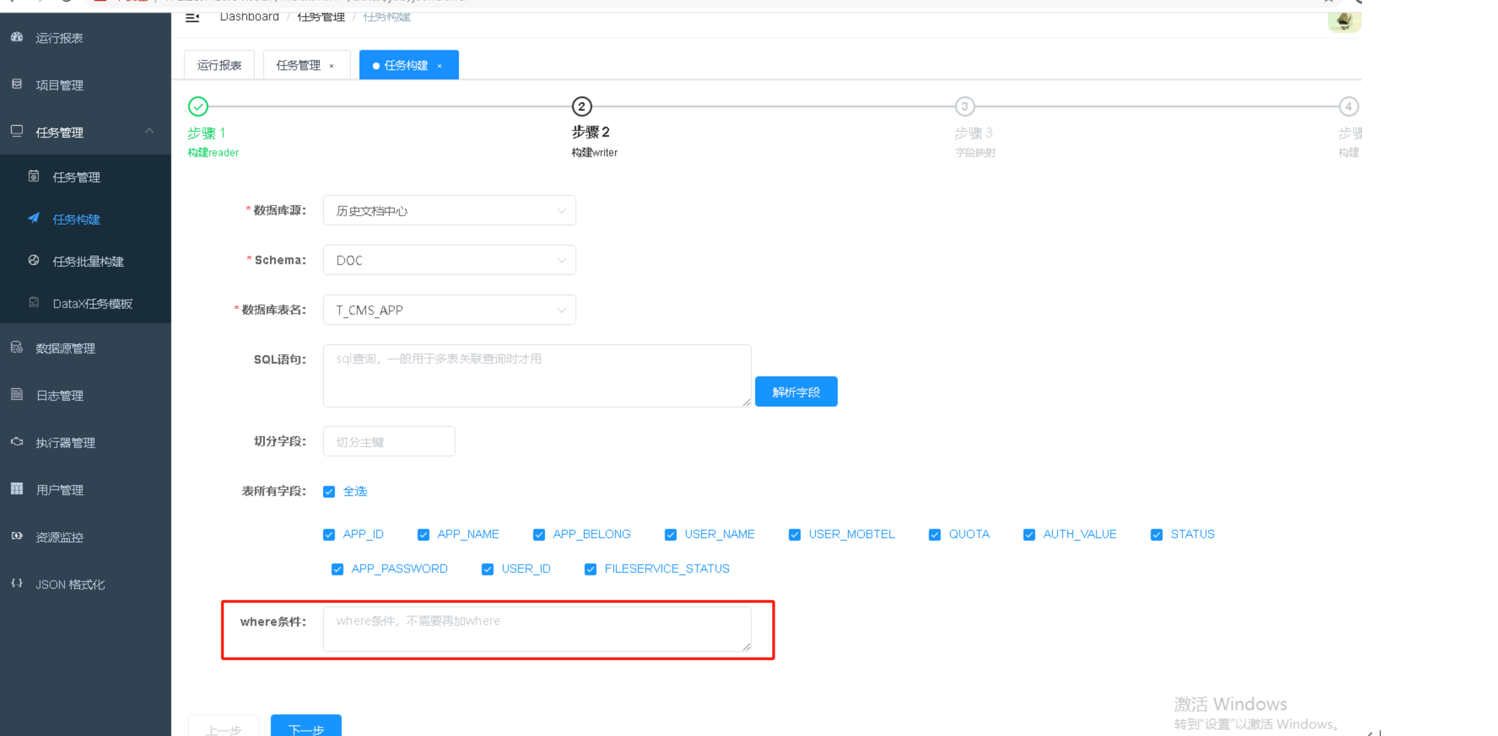
|
||||
已创建的任务,可对任务进行编辑,在下方的脚本中增加where条件和writeMode写入模式。
|
||||
|
||||
|
||||
3.2 全量数据同步json配置示例【注意:同步数据前,会删除目标表的全部数据】
|
||||
{
|
||||
"job": {
|
||||
"setting": {
|
||||
@@ -110,7 +135,7 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
"T_CMS_D_PAPER_AUTH"
|
||||
],
|
||||
"jdbcUrl": [
|
||||
"jdbc:oracle:thin:@//10.158.129.136:1521/wportal"
|
||||
"jdbc:oracle:thin:@//10.158.xxx.xxx:1521/wportal"
|
||||
]
|
||||
}
|
||||
]
|
||||
@@ -136,7 +161,7 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
"table": [
|
||||
"t_cms_d_paper_auth"
|
||||
],
|
||||
"jdbcUrl": "jdbc:mysql://172.28.145.61:3306/cz_doc"
|
||||
"jdbcUrl": "jdbc:mysql://172.28.xxx.xxx:3306/cz_doc"
|
||||
}
|
||||
]
|
||||
}
|
||||
@@ -146,7 +171,7 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
}
|
||||
}
|
||||
|
||||
3.3 增量数据同步配置
|
||||
3.3 增量数据同步json配置示例
|
||||
{
|
||||
"job": {
|
||||
"setting": {
|
||||
@@ -190,7 +215,7 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
"T_FILE"
|
||||
],
|
||||
"jdbcUrl": [
|
||||
"jdbc:oracle:thin:@//10.158.129.136:1521/wportal"
|
||||
"jdbc:oracle:thin:@//10.158.xxx.xxx:1521/wportal"
|
||||
]
|
||||
}
|
||||
]
|
||||
@@ -223,7 +248,7 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
"table": [
|
||||
"t_file"
|
||||
],
|
||||
"jdbcUrl": "jdbc:mysql://172.28.145.61:3306/cz_doc"
|
||||
"jdbcUrl": "jdbc:mysql://172.28.xxx.xxx:3306/cz_doc"
|
||||
}
|
||||
]
|
||||
}
|
||||
@@ -233,6 +258,8 @@ python /opt/datax/bin/datax.py /opt/datax/job/xx.json
|
||||
}
|
||||
}
|
||||
可通过where 语句,设定同步几天之内的数据。
|
||||
|
||||
全文结束。如您还有疑问,可联系高佳18627548877,获取进一步的指导。
|
||||
<!--stackedit_data:
|
||||
eyJoaXN0b3J5IjpbMTY1OTMxMTc1MiwtOTU3MTkyMjc5XX0=
|
||||
eyJoaXN0b3J5IjpbLTE0NTc1MDMzODUsLTk1NzE5MjI3OV19
|
||||
-->
|
||||
Reference in New Issue
Block a user