245 lines
21 KiB
Markdown
245 lines
21 KiB
Markdown

|
||
## 写在前面
|
||
本文组织方式:
|
||
|
||
1. **K8S的架构、作用和目的。需要首先对K8S整体有所了解。**
|
||
K8S是什么?
|
||
为什么是K8S?
|
||
K8S怎么做?
|
||
|
||
1. **K8S的重要概念,即K8S的API对象。要学习和使用K8S必须知道和掌握的几个对象。**
|
||
Pod 实例
|
||
Volume 数据卷
|
||
Container 容器
|
||
Deployment 和 ReplicaSet
|
||
Service和Ingress
|
||
namespace 命名空间
|
||
其他
|
||
## I. K8S概览
|
||
### 1.1 K8S是什么?
|
||
K8S是[Kubernetes](https://kubernetes.io/zh/docs/concepts/overview/what-is-kubernetes/)的全称,官方称其是:
|
||
|
||
> Kubernetes is an open source system for managing [containerized applications](https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/) across multiple hosts. It provides basic mechanisms for deployment, maintenance, and scaling of applications.
|
||
> 用于自动部署、扩展和管理“容器化(containerized)应用程序”的开源系统。
|
||
|
||
翻译成大白话就是:**“K8S是负责自动化运维管理多个Docker程序的集群”。** 那么问题来了:Docker运行可方便了,为什么要用K8S,它有什么优势?
|
||
插一句题外话:
|
||
|
||
- 为什么Kubernetes要叫Kubernetes呢?维基百科已经交代了(老美对星际是真的痴迷):
|
||
Kubernetes(在希腊语意为“舵手”或“驾驶员”)由Joe Beda、Brendan Burns和Craig
|
||
McLuckie创立,并由其他谷歌工程师,包括Brian Grant和Tim Hockin等进行加盟创作,并由谷歌在2014年首次对外宣布
|
||
。该系统的开发和设计都深受谷歌的Borg系统的影响,其许多顶级贡献者之前也是Borg系统的开发者。在谷歌内部,Kubernetes的原始代号曾经是Seven,即星际迷航中的Borg(博格人)。Kubernetes标识中舵轮有七个轮辐就是对该项目代号的致意。
|
||
- 为什么Kubernetes的缩写是K8S呢?我个人赞同Why Kubernetes is Abbreviated
|
||
k8s中说的观点“嘛,写全称也太累了吧,不如整个缩写”。其实只保留首位字符,用具体数字来替代省略的字符个数的做法,还是比较常见的。
|
||
### 1.2 为什么是K8S?
|
||
试想下传统的后端部署办法:把程序包(包括可执行二进制文件、配置文件等)放到服务器上,接着运行启动脚本把程序跑起来,同时启动守护脚本定期检查程序运行状态、必要的话重新拉起程序。
|
||
|
||
有问题吗?显然有!最大的一个问题在于:**如果服务的请求量上来,已部署的服务响应不过来怎么办?** 传统的做法往往是,如果请求量、内存、CPU超过阈值做了告警,运维马上再加几台服务器,部署好服务之后,接入负载均衡来分担已有服务的压力。
|
||
|
||
问题出现了:从监控告警到部署服务,中间需要人力介入!那么,**有没有办法自动完成服务的部署、更新、卸载和扩容、缩容呢?**
|
||
|
||
**这,就是K8S要做的事情:自动化运维管理Docker(容器化)程序。**
|
||
|
||
### 1.3 K8S怎么做?
|
||
我们已经知道了K8S的核心功能:自动化运维管理多个容器化程序。那么K8S怎么做到的呢?这里,我们从宏观架构上来学习K8S的设计思想。首先看下图,图片来自文章Components of Kubernetes Architecture:
|
||

|
||
K8S是属于**主从设备模型(Master-Slave架构)**,即有Master节点负责核心的调度、管理和运维,Slave节点则在执行用户的程序。但是在K8S中,主节点一般被称为**Master Node或者Head Node**(本文采用Master Node称呼方式),而从节点则被称为**Worker Node或者Node**(本文采用Worker Node称呼方式)。
|
||
|
||
要注意一点:Master Node和Worker Node是分别安装了K8S的Master和Woker组件的实体服务器,每个Node都对应了一台实体服务器(虽然Master Node可以和其中一个Worker Node安装在同一台服务器,但是建议Master Node单独部署),**所有Master Node和Worker Node组成了K8S集群**,同一个集群可能存在多个Master Node和Worker Node。
|
||
|
||
首先来看**Master Node**都有哪些组件:
|
||
|
||
- **API Server。K8S的请求入口服务**。API Server负责接收K8S所有请求(来自UI界面或者CLI命令行工具),然后,API
|
||
Server根据用户的具体请求,去通知其他组件干活。
|
||
- **Scheduler。K8S所有Worker Node的调度器**。当用户要部署服务时,Scheduler会选择最合适的Worker Node(服务器)来部署。
|
||
- **Controller Manager。K8S所有Worker Node的监控器**。Controller Manager有很多具体的Controller,在文章Components of Kubernetes Architecture中提到的有Node Controller、Service Controller、Volume Controller等。Controller负责监控和调整在Worker Node上部署的服务的状态,比如用户要求A服务部署2个副本,那么当其中一个服务挂了的时候,Controller会马上调整,让Scheduler再选择一个Worker Node重新部署服务。
|
||
- **etcd。K8S的存储服务**。etcd存储了K8S的关键配置和用户配置,K8S中仅API Server才具备读写权限,其他组件必须通过API
|
||
Server的接口才能读写数据(见Kubernetes Works Like an Operating System)。
|
||
|
||
接着来看**Worker Node**的组件,笔者更赞同[HOW DO APPLICATIONS RUN ON KUBERNETES](https://thenewstack.io/how-do-applications-run-on-kubernetes/)文章中提到的组件介绍:
|
||
|
||
- **Kubelet。Worker Node的监视器,以及与Master Node的通讯器**。Kubelet是Master
|
||
Node安插在Worker Node上的“眼线”,它会定期向Worker
|
||
Node汇报自己Node上运行的服务的状态,并接受来自Master Node的指示采取调整措施。
|
||
- **Kube-Proxy。K8S的网络代理**。私以为称呼为Network-Proxy可能更适合?Kube-Proxy负责Node在K8S的网络通讯、以及对外部网络流量的负载均衡。
|
||
- **Container Runtime。Worker Node的运行环境**。即安装了容器化所需的软件环境确保容器化程序能够跑起来,比如Docker Engine。大白话就是帮忙装好了Docker运行环境。
|
||
- **Logging Layer。K8S的监控状态收集器**。私以为称呼为Monitor可能更合适?Logging
|
||
Layer负责采集Node上所有服务的CPU、内存、磁盘、网络等监控项信息。
|
||
- **Add-Ons。K8S管理运维Worker Node的插件组件**。有些文章认为Worker
|
||
Node只有三大组件,不包含Add-On,但笔者认为K8S系统提供了Add-On机制,让用户可以扩展更多定制化功能,是很不错的亮点。
|
||
|
||
总结来看,**K8S的Master Node具备:请求入口管理(API Server),Worker Node调度(Scheduler),监控和自动调节(Controller Manager),以及存储功能(etcd);而K8S的Worker Node具备:状态和监控收集(Kubelet),网络和负载均衡(Kube-Proxy)、保障容器化运行环境(Container Runtime)、以及定制化功能(Add-Ons)**。
|
||
|
||
## II. K8S重要概念
|
||
### 2.1 Pod实例
|
||
官方对于Pod的解释是:
|
||
|
||
> Pod是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
|
||
|
||
这样的解释还是很难让人明白究竟Pod是什么,但是对于K8S而言,Pod可以说是所有对象中最重要的概念了!因此,我们**必须首先清楚地知道“Pod是什么”**,再去了解其他的对象。
|
||
|
||
从官方给出的定义,联想下“最小的xxx单元”,是不是可以想到本科在学校里学习“进程”的时候,教科书上有一段类似的描述:资源分配的最小单位;还有”线程“的描述是:CPU调度的最小单位。什么意思呢?”**最小xx单位“要么就是事物的衡量标准单位,要么就是资源的闭包、集合**。前者比如长度米、时间秒;后者比如一个”进程“是存储和计算的闭包,一个”线程“是CPU资源(包括寄存器、ALU等)的闭包。
|
||
|
||
同样的,**Pod就是K8S中一个服务的闭包**。这么说的好像还是有点玄乎,更加云里雾里了。简单来说,**Pod可以被理解成一群可以共享网络、存储和计算资源的容器化服务的集合**。再打个形象的比喻,在同一个Pod里的几个Docker服务/程序,好像被部署在同一台机器上,可以通过localhost互相访问,并且可以共用Pod里的存储资源(这里是指Docker可以挂载Pod内的数据卷,数据卷的概念,后文会详细讲述,暂时理解为“需要手动mount的磁盘”)。笔者总结Pod如下图,可以看到:**同一个Pod之间的Container可以通过localhost互相访问,并且可以挂载Pod内所有的数据卷;但是不同的Pod之间的Container不能用localhost访问,也不能挂载其他Pod的数据卷**。
|
||

|
||
|
||
对Pod有直观的认识之后,接着来看K8S中Pod究竟长什么样子,具体包括哪些资源?
|
||
|
||
K8S中所有的对象都通过yaml来表示,笔者从[官方网站](https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-memory-resource/)摘录了一个最简单的Pod的yaml:
|
||
|
||
```bash
|
||
apiVersion: v1
|
||
kind: Pod
|
||
metadata:
|
||
name: memory-demo
|
||
namespace: mem-example
|
||
spec:
|
||
containers:
|
||
- name: memory-demo-ctr
|
||
image: polinux/stress
|
||
resources:
|
||
limits:
|
||
memory: "200Mi"
|
||
requests:
|
||
memory: "100Mi"
|
||
command: ["stress"]
|
||
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
|
||
volumeMounts:
|
||
- name: redis-storage
|
||
mountPath: /data/redis
|
||
volumes:
|
||
- name: redis-storage
|
||
emptyDir: {}
|
||
```
|
||
看不懂不必慌张,且耐心听下面的解释:
|
||
- apiVersion记录K8S的API Server版本,现在看到的都是v1,用户不用管。
|
||
- kind记录该yaml的对象,比如这是一份Pod的yaml配置文件,那么值内容就是Pod。
|
||
- metadata记录了Pod自身的元数据,比如这个Pod的名字、这个Pod属于哪个namespace(命名空间的概念,后文会详述,暂时理解为“同一个命名空间内的对象互相可见”)。
|
||
- spec记录了Pod内部所有的资源的详细信息,看懂这个很重要:
|
||
- containers记录了Pod内的容器信息,containers包括了:name容器名,image容器的镜像地址,resources容器需要的CPU、内存、GPU等资源,command容器的入口命令,args容器的入口参数,volumeMounts容器要挂载的Pod数据卷等。可以看到,**上述这些信息都是启动容器的必要和必需的信息。**
|
||
- volumes记录了Pod内的数据卷信息,后文会详细介绍Pod的数据卷。
|
||
|
||
### 2.2 Volume 数据卷
|
||
K8S支持很多类型的volume数据卷挂载,具体请参见[K8S卷](https://kubernetes.io/zh/docs/concepts/storage/volumes/)。前文就“如何理解volume”提到:“需要手动mount的磁盘”,此外,有一点可以帮助理解:数据卷volume是Pod内部的磁盘资源。
|
||
|
||
其实,单单就Volume来说,不难理解。但是上面还看到了volumeMounts,这俩是什么关系呢?
|
||
|
||
volume是K8S的对象,对应一个实体的数据卷;而volumeMounts只是container的挂载点,对应container的其中一个参数。但是,volumeMounts依赖于volume,只有当Pod内有volume资源的时候,该Pod内部的container才可能有volumeMounts。
|
||
|
||
|
||
### 2.3 Container 容器
|
||
本文中提到的镜像Image、容器Container,都指代了Pod下的一个container。关于K8S中的容器,在2.1Pod章节都已经交代了,这里无非再啰嗦一句:**一个Pod内可以有多个容器container**。
|
||
|
||
在Pod中,容器也有分类,对这个感兴趣的同学欢迎自行阅读更多资料:
|
||
|
||
- **标准容器 Application Container**。
|
||
- **初始化容器 Init Container**。
|
||
- **边车容器 Sidecar Container**。
|
||
- **临时容器 Ephemeral Container**。
|
||
|
||
一般来说,我们部署的大多是**标准容器( Application Container)**。
|
||
|
||
### 2.4 Deployment 和 ReplicaSet(简称RS)
|
||
除了Pod之外,K8S中最常听到的另一个对象就是Deployment了。那么,什么是Deployment呢?官方给出了一个要命的解释:
|
||
|
||
> 一个 Deployment 控制器为 Pods 和 ReplicaSets 提供声明式的更新能力。 你负责描述 Deployment 中的
|
||
> 目标状态,而 Deployment 控制器以受控速率更改实际状态, 使其变为期望状态。你可以定义 Deployment 以创建新的
|
||
> ReplicaSet,或删除现有 Deployment,并通过新的 Deployment 收养其资源。
|
||
|
||
翻译一下:**Deployment的作用是管理和控制Pod和ReplicaSet,管控它们运行在用户期望的状态中**。哎,打个形象的比喻,**Deployment就是包工头**,主要负责监督底下的工人Pod干活,确保每时每刻有用户要求数量的Pod在工作。如果一旦发现某个工人Pod不行了,就赶紧新拉一个Pod过来替换它。
|
||
|
||
新的问题又来了:那什么是ReplicaSets呢?
|
||
|
||
> ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的
|
||
> Pod 的可用性。
|
||
|
||
再来翻译下:ReplicaSet的作用就是管理和控制Pod,管控他们好好干活。但是,ReplicaSet受控于Deployment。形象来说,**ReplicaSet就是总包工头手下的小包工头**。
|
||
|
||
笔者总结得到下面这幅图,希望能帮助理解:
|
||

|
||
新的问题又来了:**如果都是为了管控Pod好好干活,为什么要设置Deployment和ReplicaSet两个层级呢,直接让Deployment来管理不可以吗?**
|
||
|
||
回答:不清楚,但是私以为是因为先有ReplicaSet,但是使用中发现ReplicaSet不够满足要求,于是又整了一个Deployment(**有清楚Deployment和ReplicaSet联系和区别的小伙伴欢迎留言啊**)。
|
||
|
||
但是,从K8S使用者角度来看,用户会直接操作Deployment部署服务,而当Deployment被部署的时候,K8S会自动生成要求的ReplicaSet和Pod。在[K8S官方文档](https://www.kubernetes.org.cn/replicasets)中也指出用户只需要关心Deployment而不操心ReplicaSet:
|
||
|
||
> This actually means that you may never need to manipulate ReplicaSet
|
||
> objects: use a Deployment instead, and define your application in the
|
||
> spec section.
|
||
> 这实际上意味着您可能永远不需要操作ReplicaSet对象:直接使用Deployments并在规范部分定义应用程序。
|
||
|
||
补充说明:在K8S中还有一个对象 --- ReplicationController(简称RC),官方文档对它的定义是:
|
||
|
||
> ReplicationController 确保在任何时候都有特定数量的 Pod 副本处于运行状态。
|
||
> 换句话说,ReplicationController 确保一个 Pod 或一组同类的 Pod 总是可用的。
|
||
|
||
怎么样,和ReplicaSet是不是很相近?在Deployments, ReplicaSets, and pods教程中说“ReplicationController是ReplicaSet的前身”,官方也推荐用Deployment取代ReplicationController来部署服务。
|
||
|
||
### 2.5 Service和Ingress
|
||
吐槽下K8S的概念/对象/资源是真的多啊!**前文介绍的Deployment、ReplicationController和ReplicaSet主要管控Pod程序服务;那么,Service和Ingress则负责管控Pod网络服务**。
|
||
|
||
我们先来看看官方文档中Service的定义:
|
||
|
||
> 将运行在一组 [Pods](https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/) 上的应用程序公开为网络服务的抽象方法。 使用 Kubernetes,您无需修改应用程序即可使用不熟悉的服务发现机制。
|
||
> Kubernetes 为 Pods 提供自己的 IP 地址,并为一组 Pod 提供相同的 DNS 名, 并且可以在它们之间进行负载均衡。
|
||
|
||
翻译下:K8S中的服务(Service)并不是我们常说的“服务”的含义,而更像是网关层,是若干个Pod的流量入口、流量均衡器。
|
||
那么,**为什么要Service呢?**
|
||
|
||
私以为在这一点上,[官方文档](https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/namespaces/)讲解地非常清楚:
|
||
|
||
> Kubernetes Pod 是有生命周期的。 它们可以被创建,而且销毁之后不会再启动。 如果您使用 Deployment
|
||
> 来运行您的应用程序,则它可以动态创建和销毁 Pod。 每个 Pod 都有自己的 IP 地址,但是在 Deployment
|
||
> 中,在同一时刻运行的 Pod 集合可能与稍后运行该应用程序的 Pod 集合不同。 这导致了一个问题: 如果一组
|
||
> Pod(称为“后端”)为群集内的其他 Pod(称为“前端”)提供功能, 那么前端如何找出并跟踪要连接的 IP
|
||
> 地址,以便前端可以使用工作量的后端部分?
|
||
|
||
补充说明:K8S集群的网络管理和拓扑也有特别的设计,以后会专门出一章节来详细介绍K8S中的网络。这里需要清楚一点:K8S集群内的每一个Pod都有自己的IP(是不是很类似一个Pod就是一台服务器,然而事实上是多个Pod存在于一台服务器上,只不过是K8S做了网络隔离),在K8S集群内部还有DNS等网络服务(一个K8S集群就如同管理了多区域的服务器,可以做复杂的网络拓扑)。
|
||
|
||
此外,笔者推荐k8s外网如何访问业务应用对于Service的介绍,不过对于新手而言,推荐阅读前半部分对于service的介绍即可,后半部分就太复杂了。我这里做了简单的总结:
|
||
|
||
**Service是K8S服务的核心,屏蔽了服务细节,统一对外暴露服务接口,真正做到了“微服务”**。举个例子,我们的一个服务A,部署了3个备份,也就是3个Pod;对于用户来说,只需要关注一个Service的入口就可以,而不需要操心究竟应该请求哪一个Pod。优势非常明显:**一方面外部用户不需要感知因为Pod上服务的意外崩溃、K8S重新拉起Pod而造成的IP变更,外部用户也不需要感知因升级、变更服务带来的Pod替换而造成的IP变化,另一方面,Service还可以做流量负载均衡**。
|
||
|
||
但是,Service主要负责K8S集群内部的网络拓扑。那么集群外部怎么访问集群内部呢?这个时候就需要Ingress了,[官方文档](https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/namespaces/)中的解释是:
|
||
|
||
> Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。 Ingress 可以提供负载均衡、SSL
|
||
> 终结和基于名称的虚拟托管。
|
||
|
||
翻译一下:Ingress是整个K8S集群的接入层,复杂集群内外通讯。
|
||
|
||
最后,笔者把Ingress和Service的关系绘制网络拓扑关系图如下,希望对理解这两个概念有所帮助:
|
||

|
||
### 2.6 namespace 命名空间
|
||
和前文介绍的所有的概念都不一样,namespace跟Pod没有直接关系,而是K8S另一个维度的对象。或者说,前文提到的概念都是为了服务Pod的,而namespace则是为了服务整个K8S集群的。
|
||
|
||
那么,namespace是什么呢?
|
||
|
||
上[官方文档](https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/namespaces/)定义:
|
||
|
||
> Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为名字空间。
|
||
|
||
翻译一下:**namespace是为了把一个K8S集群划分为若干个资源不可共享的虚拟集群而诞生的。**
|
||
|
||
也就是说,**可以通过在K8S集群内创建namespace来分隔资源和对象**。比如我有2个业务A和B,那么我可以创建ns-a和ns-b分别部署业务A和B的服务,如在ns-a中部署了一个deployment,名字是hello,返回用户的是“hello a”;在ns-b中也部署了一个deployment,名字恰巧也是hello,返回用户的是“hello b”(要知道,在同一个namespace下deployment不能同名;但是不同namespace之间没有影响)。前文提到的所有对象,都是在namespace下的;当然,也有一些对象是不隶属于namespace的,而是在K8S集群内全局可见的,官方文档提到的可以通过命令来查看,具体命令的使用办法,笔者会出后续的实战文章来介绍,先贴下命令:
|
||
|
||
```bash
|
||
# 位于名字空间中的资源
|
||
kubectl api-resources --namespaced=true
|
||
|
||
# 不在名字空间中的资源
|
||
kubectl api-resources --namespaced=false
|
||
```
|
||
不在namespace下的对象有:
|
||
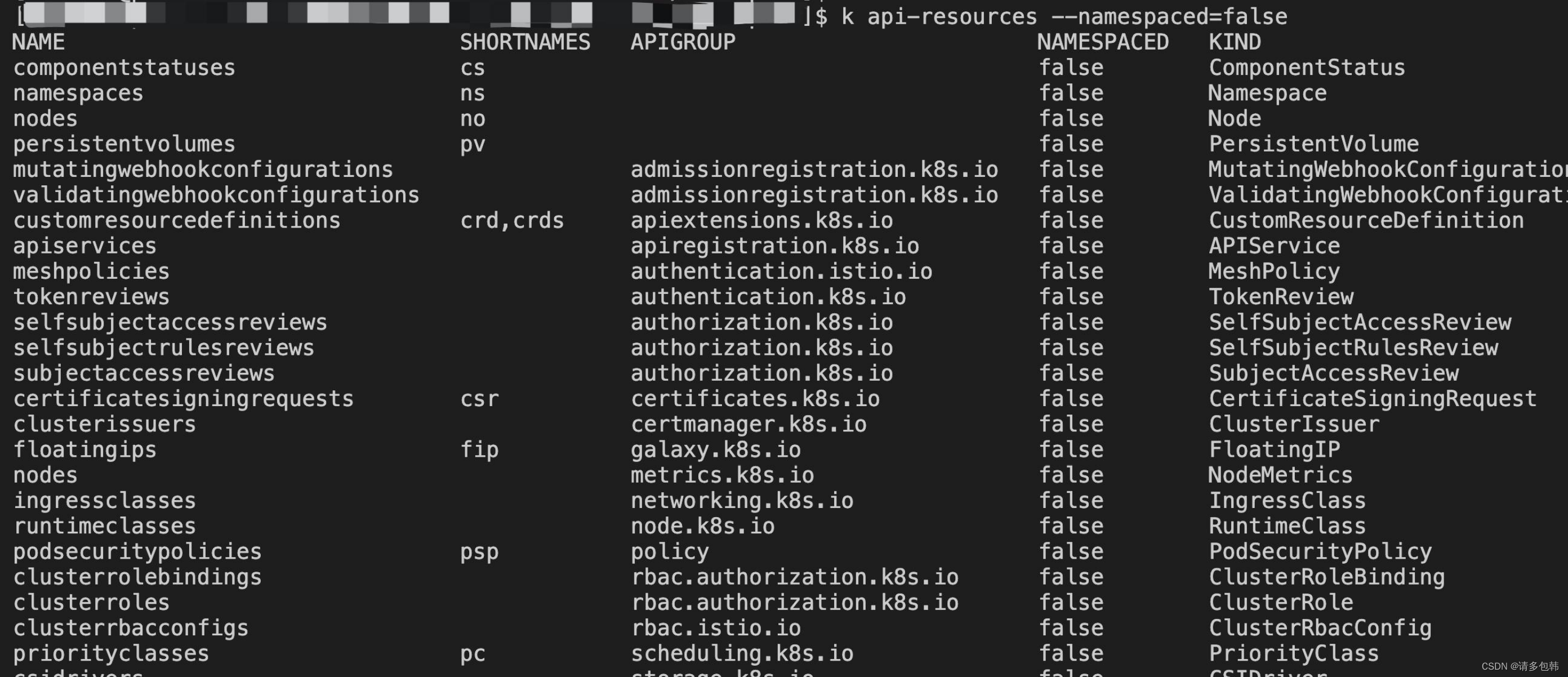
|
||
在namespace下的对象有(部分):
|
||
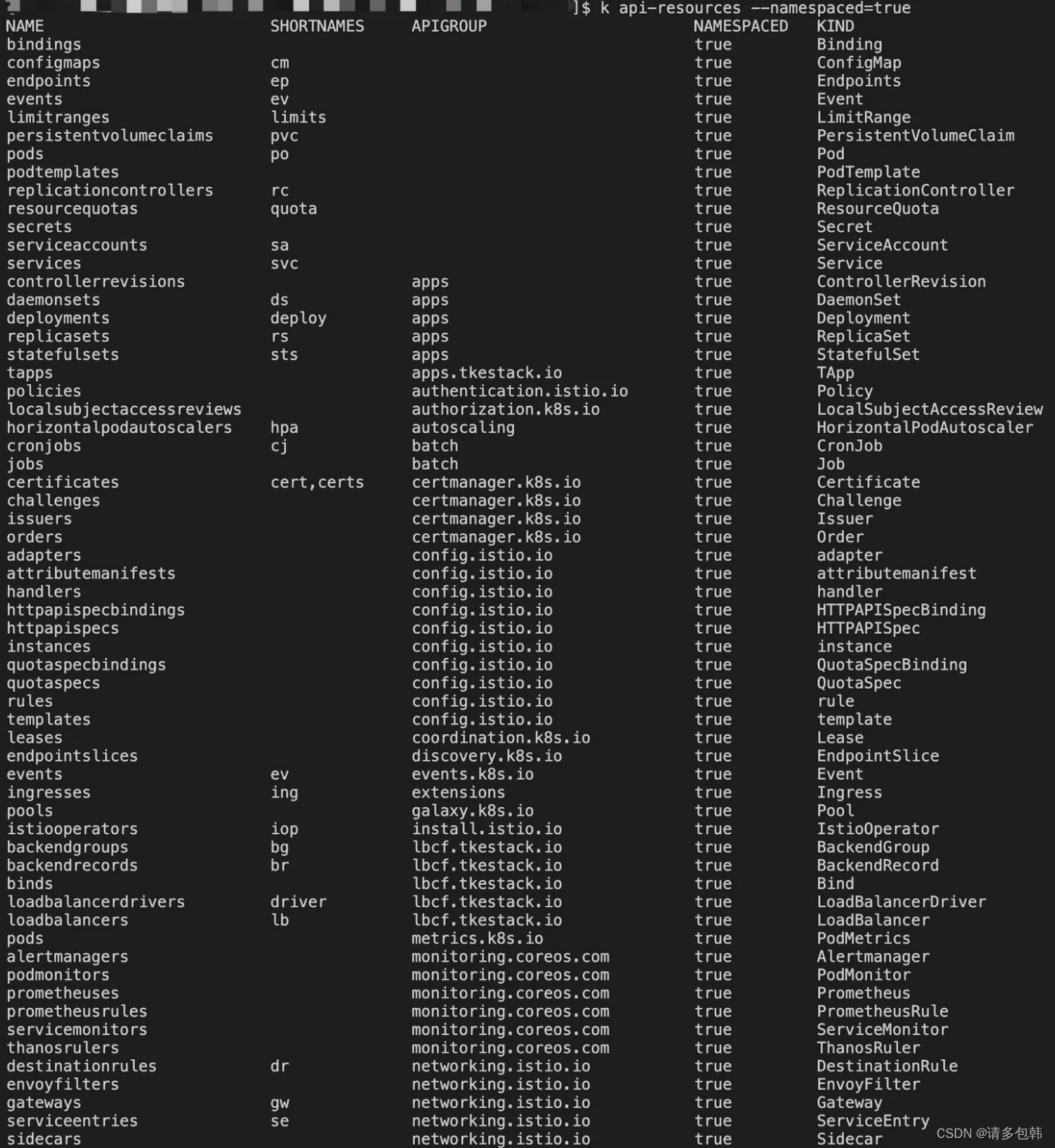
|
||
### 2.7 其他
|
||
K8S的对象实在太多了,2.1-2.6介绍的是在实际使用K8S部署服务最常见的。其他的还有Job、CronJob等等,在对K8S有了比较清楚的认知之后,再去学习更多的K8S对象,不是难事。
|
||
|
||
### 写在后面
|
||
本文是K8S系列文章第一篇,希望能够帮助对K8S不了解的新手快速了解K8S。如果文章中有纰漏,非常欢迎留言或者私信指出;有理解错误的地方,更是欢迎留言或者私信告知。
|
||
|
||
笔者一边写文章,一边查阅和整理K8S资料,过程中越发感觉K8S架构的完备、设计的精妙,是值得深入研究的,K8S大受欢迎是有道理的!再次感叹下。
|
||
<!--stackedit_data:
|
||
eyJoaXN0b3J5IjpbLTc5ODg4ODk0NF19
|
||
--> |