12 KiB
auth: 高佳、韩健 (一) 术语介绍 DataX是一个开源的数据同步工具,而DataX-Web是构建在DataX之上的分布式数据同步工具,提供了可视化的操作界面。具体来说:
- DataX:DataX的主要作用是实现不同数据源之间的离线数据同步,它支持包括关系型数据库(例如MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等多种异构数据源之间的稳定高效的数据迁移工作。DataX通过提供命令行工具和JSON配置文件的方式来执行数据同步任务,但这种方式在管理和多任务处理上存在一定的局限性。
- DataX-Web:为了解决DataX在使用过程中的配置复杂性以及管理上的不便捷,DataX-Web应运而生。DataX-Web提供了一个简单易用的操作界面,降低了用户使用DataX的学习成本,并缩短了任务配置时间。此外,它还避免了配置过程中可能出现的错误,并支持远程分布式调用DataX的功能,使得多节点之间的协作变得更加容易控制。
总的来说,DataX适用于需要进行大规模数据迁移的场景,而DataX-Web则更适合需要简化操作流程和提升任务管理效率的用户。两者结合使用,可以有效提升数据处理的效率和便捷性。
(二)工具安装 一、下载tar包 github地址:https://github.com/alibaba/DataX 下载tar包地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
二、上传tar包解压并安装
上传至服务器/opt/下并解压
tar -xzvf datax.tar.gz
三、上传解压 dataX-web
链接: https://pan.baidu.com/s/1B8bb_KeyIYvpbI5s3IwCjA 提取码: 3pah
上传压缩包至服务目录,这里我上传到/usr/local/下,具体可根据自身希望上传到哪个目录就行
unzip datax-web-2.1.2.zip
四、创建datax-web数据库
sql文件在以下目录


五、修改配置文件
1.修改数据库连接
modules下的datax-admin下的conf下的bootstrap.properties


2.注意datax-executor下的bin下的env.properties的PYTOHON_PATH的配置地址,需与我们安装的datax目录一致


六、启动datax-web及访问
执行datax-web-2.1.2下的bin下的start-all.sh启动所有模块


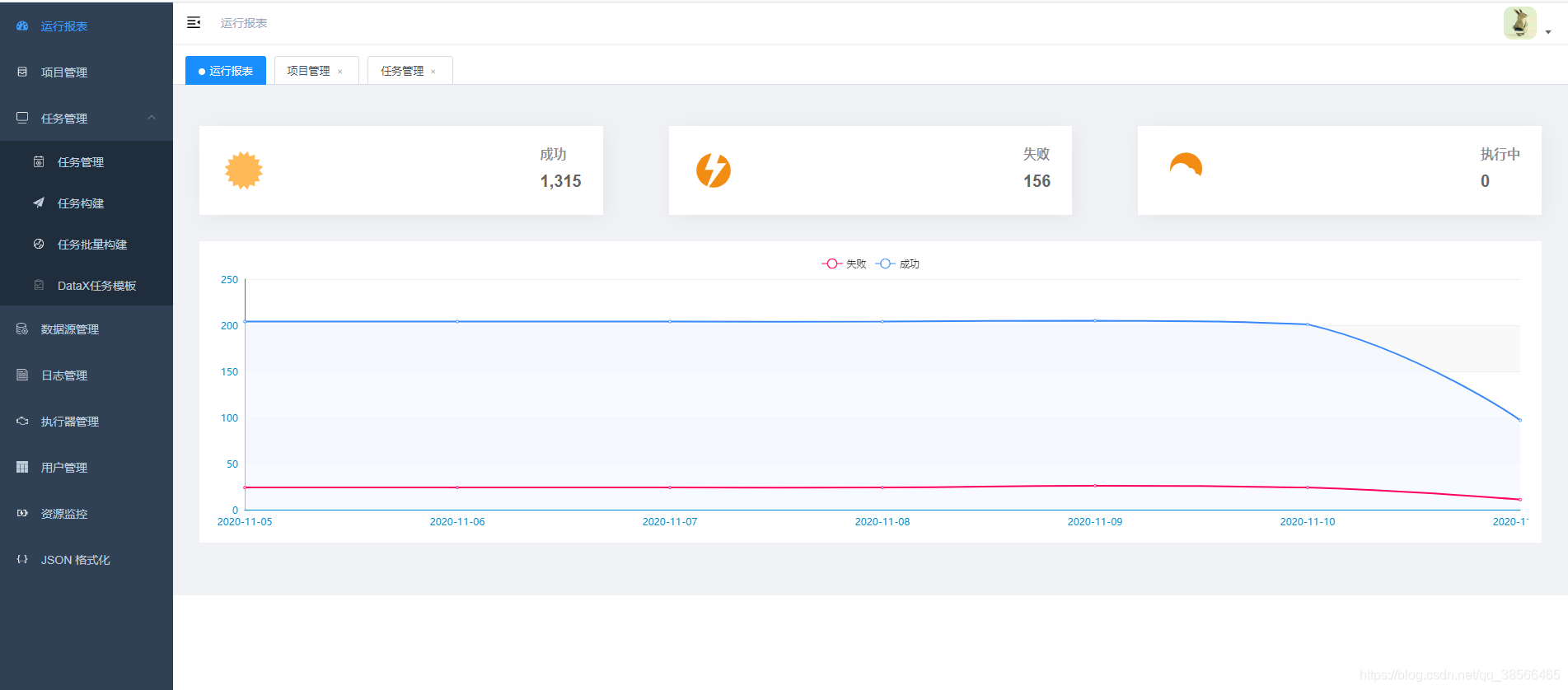
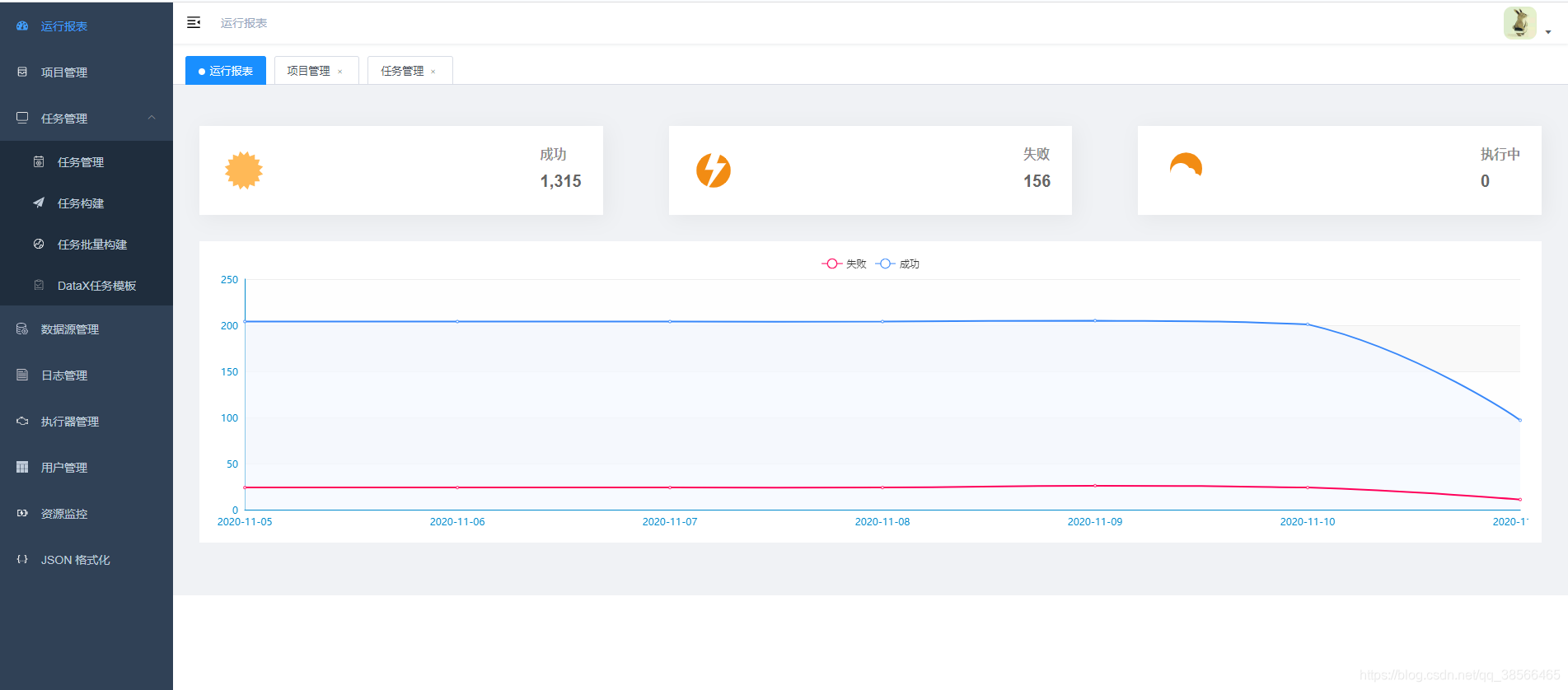
访问:http://服务器IP:9527/index.html#/dashboard
七、实际安装过程中可能会遇到的问题 1.解决Oracle没有dba权限查询用户和表失败问题 getSQLQueryTables方法sql中的dba_tables修改为all_tables。 getSQLQueryTableSchema方法sql中的dba_users修改为all_users。 通过下载源码后修改指定方法,打包jar后替换datax-admin下的lib下的datax-web-2.1.2.jar
2.解决datax写数据至db2数据库
datax暂时没有独立插件支持db2,需要使用通用RDBMS;这里是写入db2,使用rdbmswriter,对应目录为/datax/plugin/writer/rdbmswriter/
修改该目录下的plugin.json,注册数据库驱动
{
"name": "rdbmswriter",
"class": "com.alibaba.datax.plugin.reader.rdbmswriter.RdbmsWriter",
"description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
"developer": "alibaba",
"drivers":["com.ibm.db2.jcc.DB2Driver"]
}
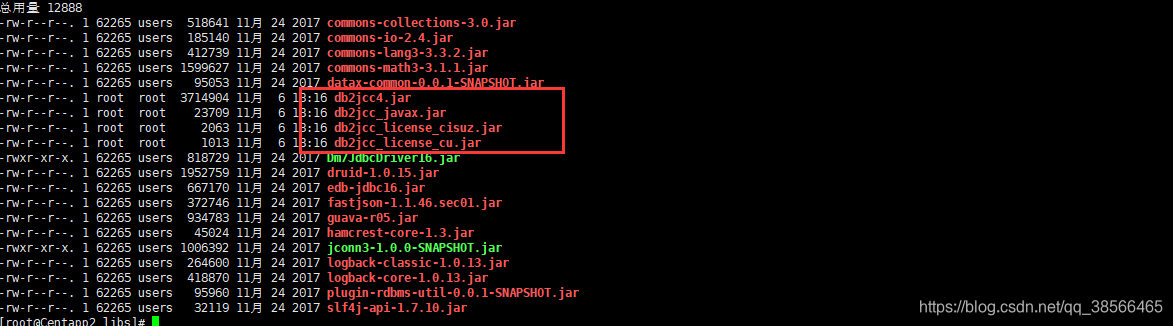
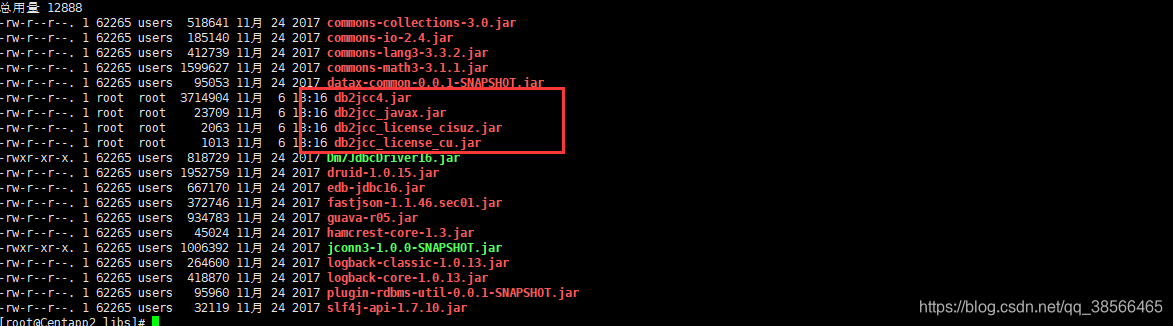
上传db2驱动到该目录下的libs,如图所示
job文件都放在/datax/job目录
创建需要执行的job的json文件


执行任务命令 python /opt/datax/bin/datax.py /opt/datax/job/xx.json
(三) 实际应用
如下为实际应用示例
3.1 如何新增任务
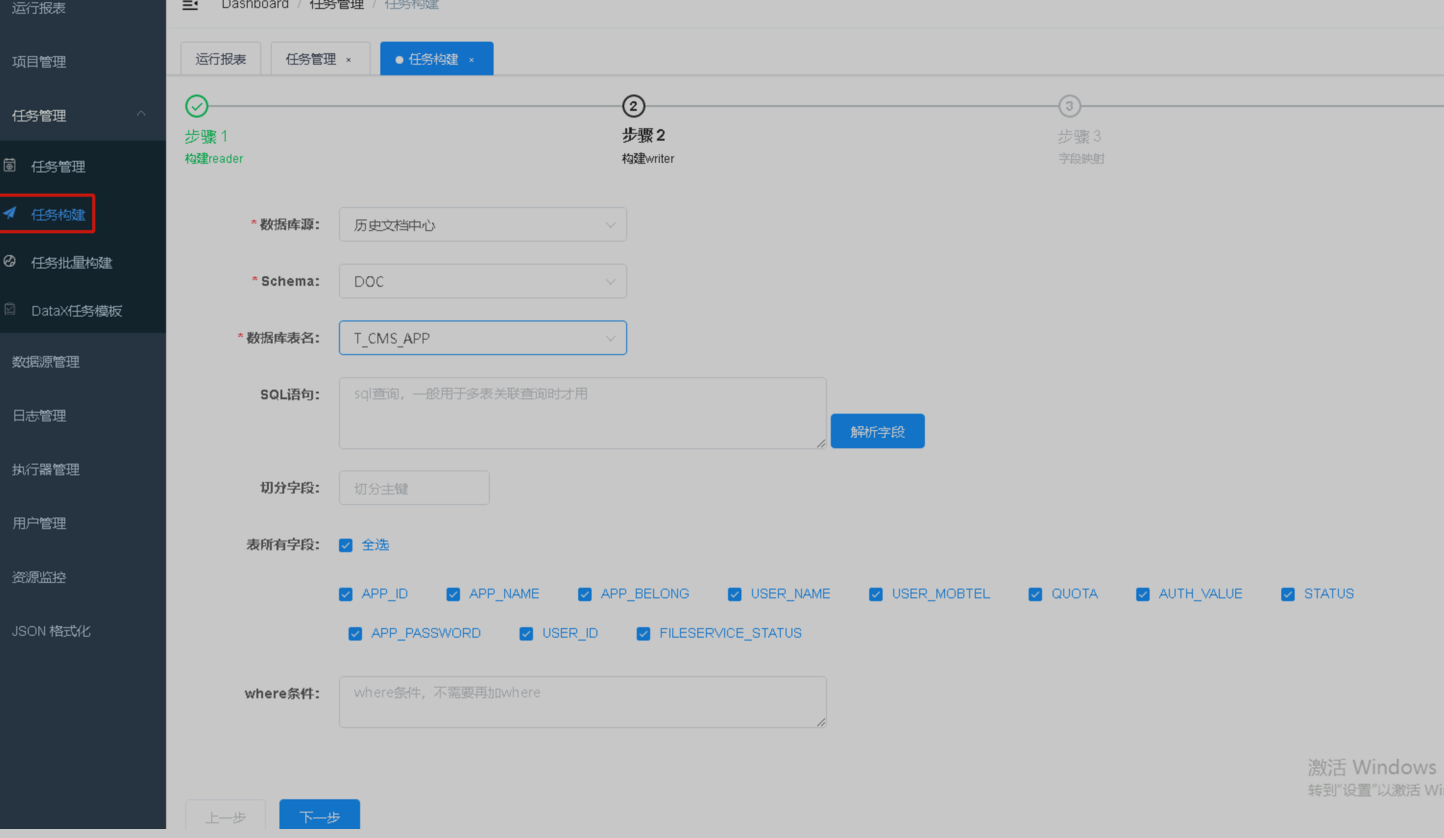
第1步首先进行任务构建,获取datax同步任务脚本,选择任务构建配置数据读取源信息。
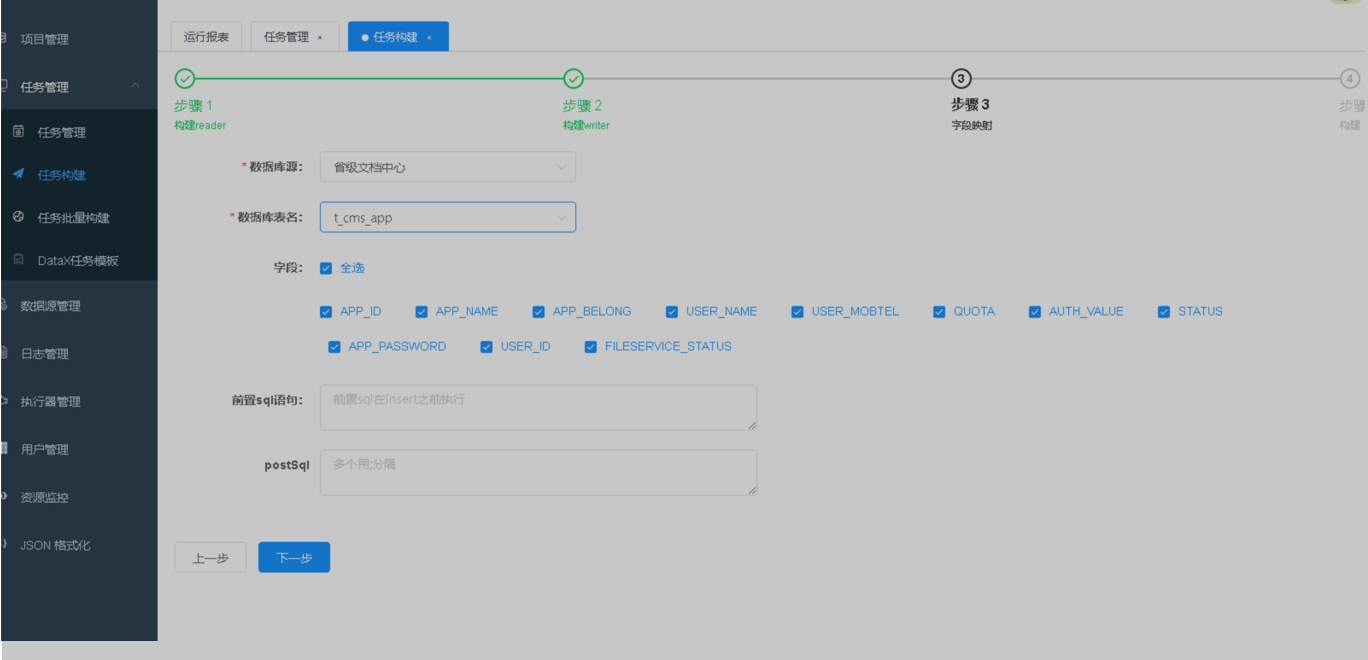
第2步配置数据写入源,前置sql语句代表执行同步前会执行的sql,例如全量同步前,对数据库清空,则在前置sql写入删除全表数据语句。
第3步 选择同步表的字段映射,比对字段数量与字段是否一致。
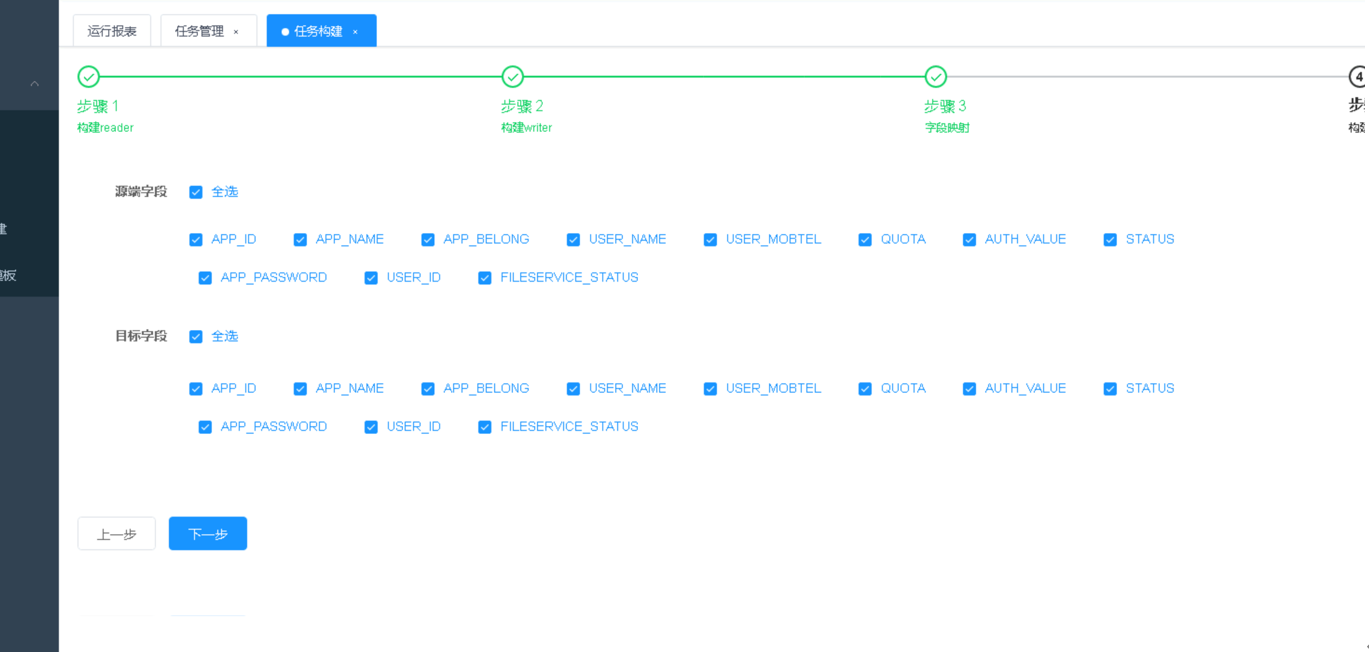
第4步点击【构建】生成datax同步任务脚本,点击【复制json】后进入任务管理。
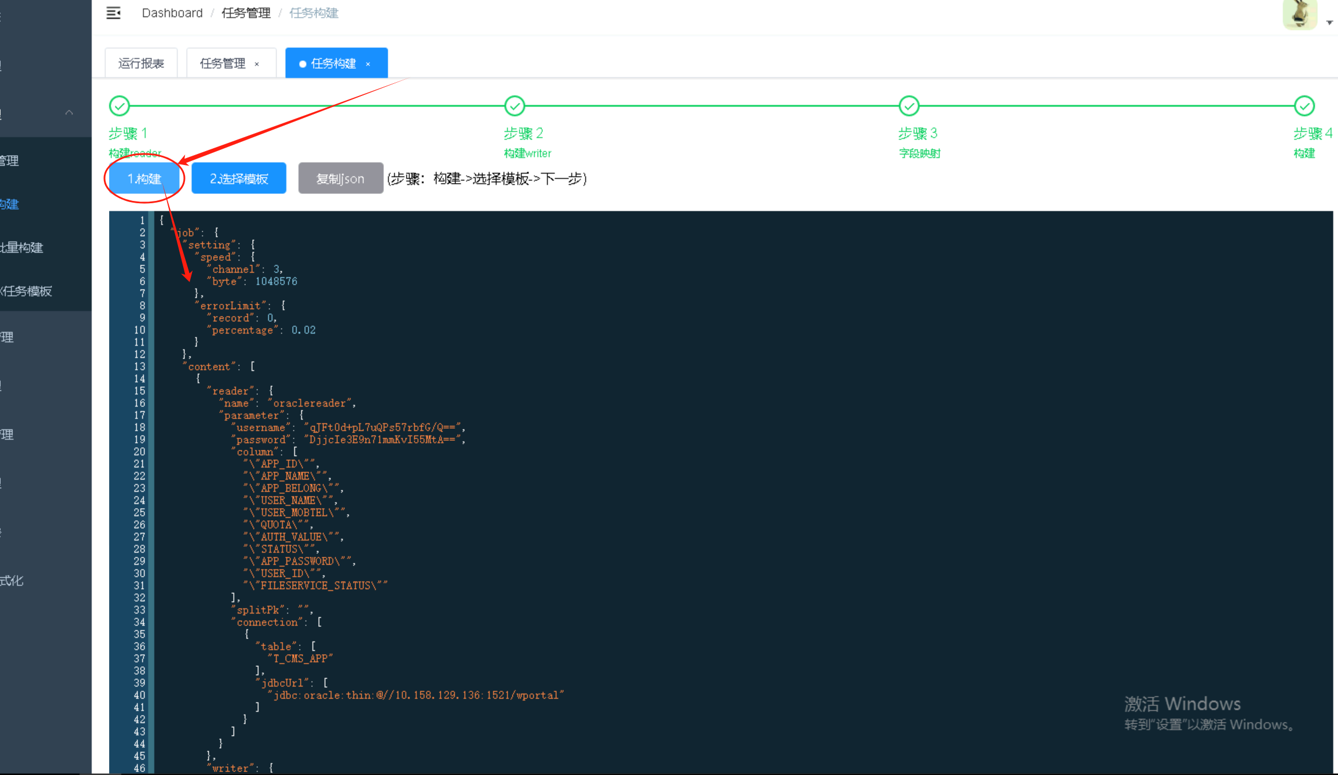
第5步进入任务管理,新增任务,执行器选择【datax执行器】,路由策略选择【轮询】,阻塞策略选择【丢弃后续调度】,任务类型选择【DataX任务】,将复制的datax任务脚本粘贴在下方的代码框内,选择所属项目,输入任务名称和配置定时触发表达式点击【确定】则完成任务的创建。
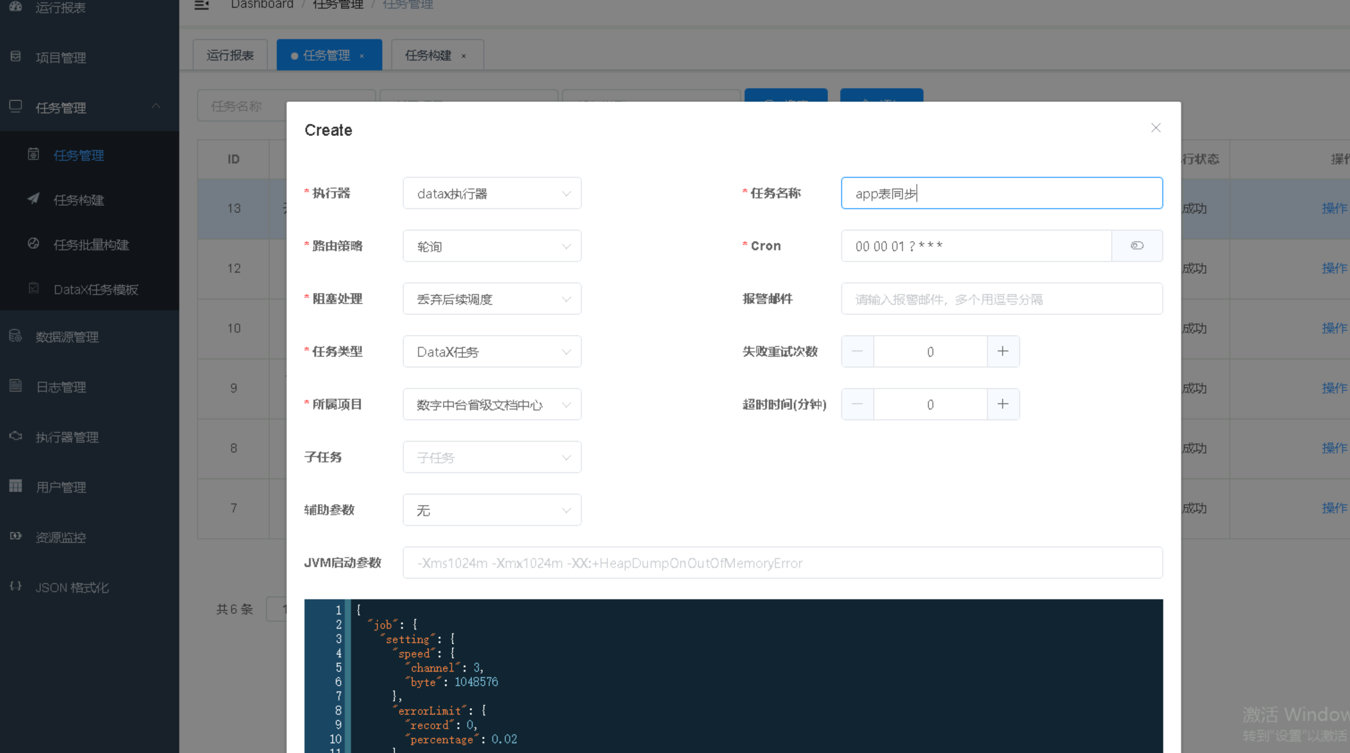
第6步任务创建完后,默认不会启动,需要点击按钮开关进行任务的启动,启动前可手动执行一次确认任务触发的逻辑和内容无误,再开启定时调度。
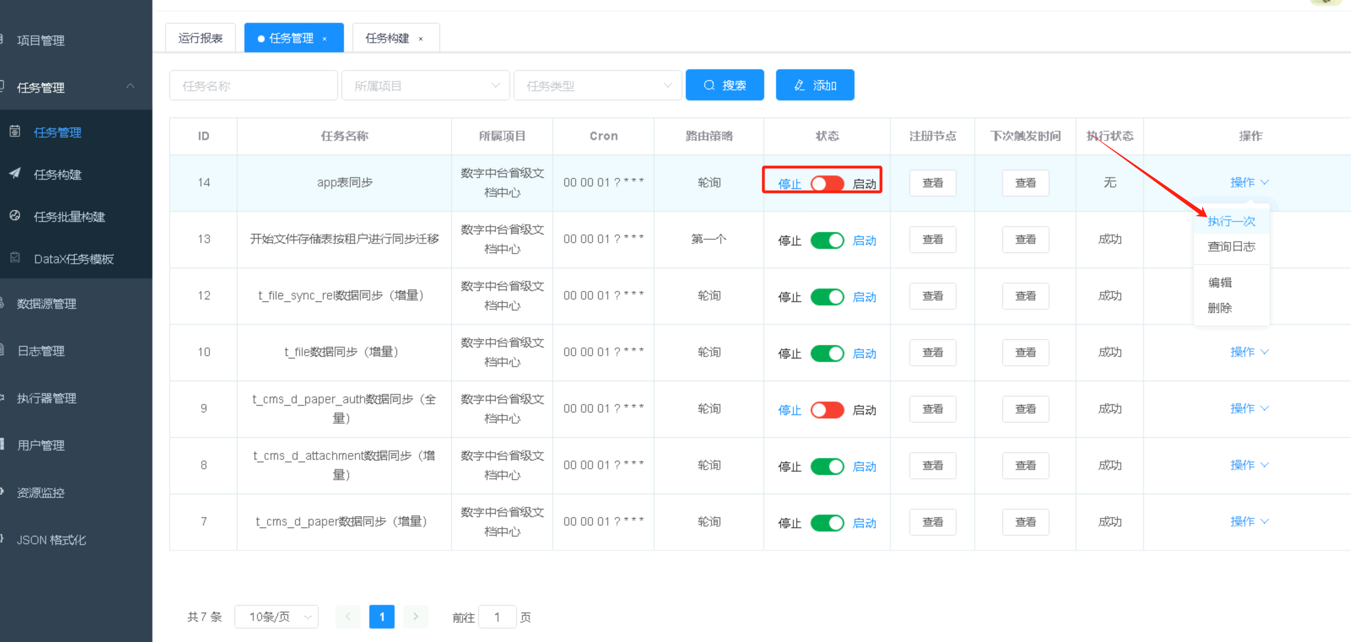
注意事项:以上创建的任务为全量同步模式,且如果目标表没进行数据清空,会存在主键冲突脏数据报错,需要调整脚本写入模式为update,这样同步会对重复数据按主键进行更新,前提为同步的表必须存在主键字段。
3.2 如何增量同步数据
在任务构建时,配置where条件,筛选条件内的数据,例如筛选2天内数据进行同步迁移(注意事项:需保证写入源的写入模式是update,"writeMode": "update")
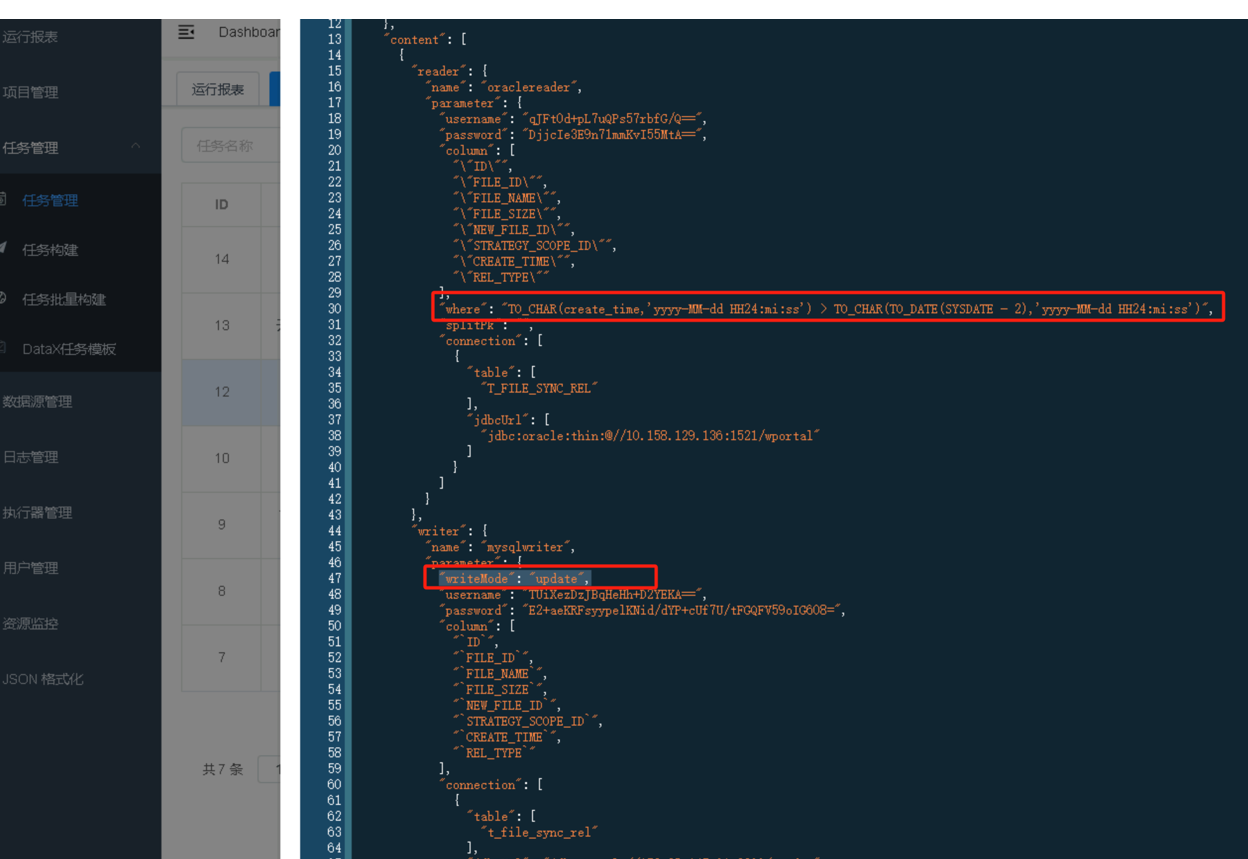
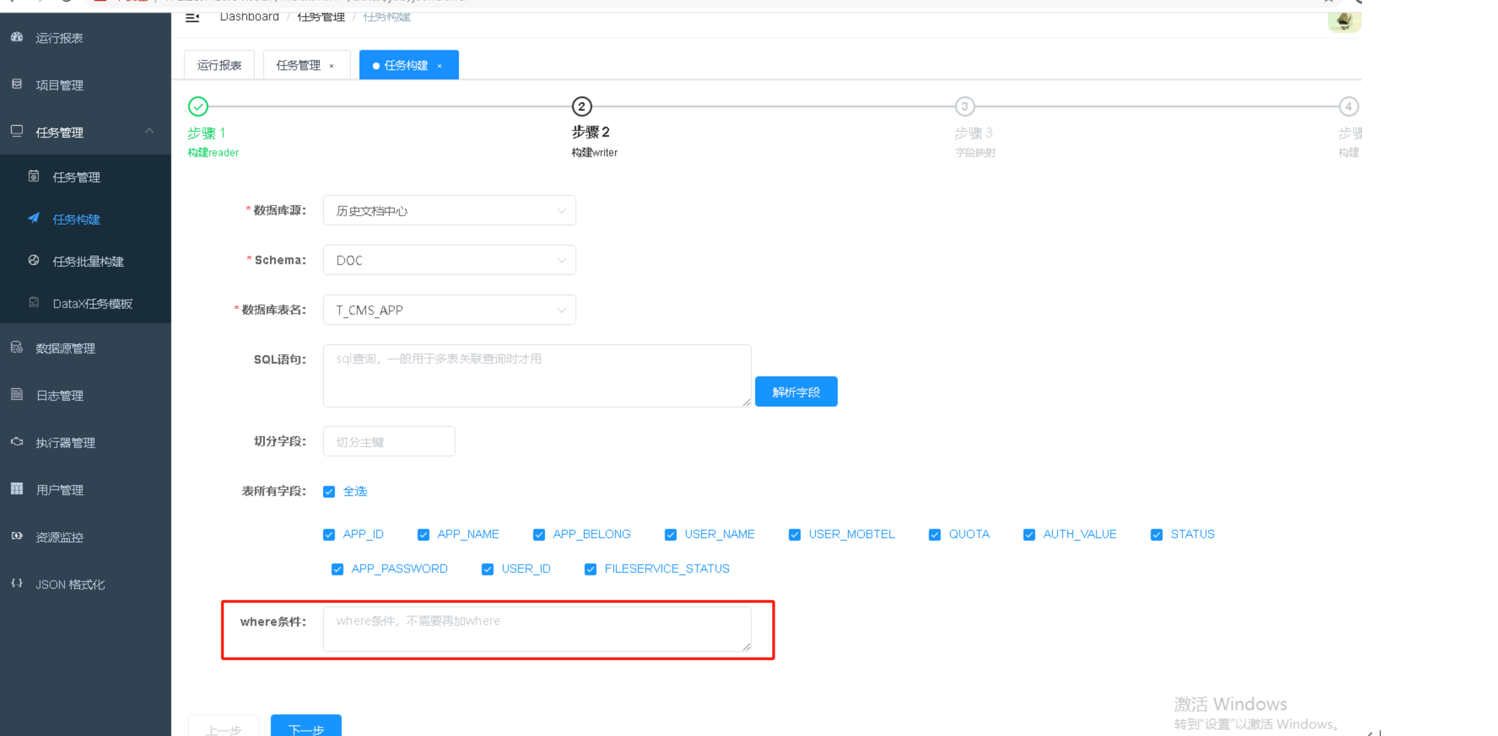 已创建的任务,可对任务进行编辑,在下方的脚本中增加where条件和writeMode写入模式。
已创建的任务,可对任务进行编辑,在下方的脚本中增加where条件和writeMode写入模式。
3.2 全量数据同步json配置示例【注意:同步数据前,会删除目标表的全部数据】
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"username": "qJFt0d+pL7uQPs57rbfG/Q==",
"password": "DjjcIe3E9n71mmKvI55MtA==",
"column": [
""PAPER_ID"",
""AUTH_OBJECT"",
""OBJECT_TYPE"",
""AUTH_VALUE""
],
"splitPk": "",
"connection": [
{
"table": [
"T_CMS_D_PAPER_AUTH"
],
"jdbcUrl": [
"jdbc:oracle:thin:@//10.158.xxx.xxx:1521/wportal"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "update",
"username": "TUiXezDzJBqHeHh+D2YEKA==",
"password": "E2+aeKRFsyypelKNid/dYP+cUf7U/tFGQFV59oIG608=",
"column": [
"PAPER_ID",
"AUTH_OBJECT",
"OBJECT_TYPE",
"AUTH_VALUE"
],
"preSql": [
"truncate table t_cms_d_paper_auth"
],
"connection": [
{
"table": [
"t_cms_d_paper_auth"
],
"jdbcUrl": "jdbc:mysql://172.28.xxx.xxx:3306/cz_doc"
}
]
}
}
}
]
}
}
3.3 增量数据同步json配置示例
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"username": "qJFt0d+pL7uQPs57rbfG/Q==",
"password": "DjjcIe3E9n71mmKvI55MtA==",
"column": [
""FILE_ID"",
""FILENAME"",
""FILE_PATH"",
""FILE_SIZE"",
""FILE_FORMAT"",
""FILE_MD5"",
""APP_ID"",
""CREATE_DATE"",
""UPDATE_DATE"",
""DELETE_FLAG"",
""DELETE_DATE"",
""BIGDATA_FILE_ID"",
""LABEL_NAME"",
""IS_UPLOAD""
],
"where": "TO_CHAR(create_date,'yyyy-MM-dd HH24:mi:ss') > TO_CHAR(TO_DATE(SYSDATE - 3),'yyyy-MM-dd HH24:mi:ss')",
"splitPk": "",
"connection": [
{
"table": [
"T_FILE"
],
"jdbcUrl": [
"jdbc:oracle:thin:@//10.158.xxx.xxx:1521/wportal"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "update",
"username": "TUiXezDzJBqHeHh+D2YEKA==",
"password": "E2+aeKRFsyypelKNid/dYP+cUf7U/tFGQFV59oIG608=",
"column": [
"FILE_ID",
"FILENAME",
"FILE_PATH",
"FILE_SIZE",
"FILE_FORMAT",
"FILE_MD5",
"APP_ID",
"CREATE_DATE",
"UPDATE_DATE",
"DELETE_FLAG",
"DELETE_DATE",
"BIGDATA_FILE_ID",
"LABEL_NAME",
"IS_UPLOAD"
],
"connection": [
{
"table": [
"t_file"
],
"jdbcUrl": "jdbc:mysql://172.28.xxx.xxx:3306/cz_doc"
}
]
}
}
}
]
}
}
可通过where 语句,设定同步几天之内的数据。
全文结束。如您还有疑问,可联系高佳18627548877,获取进一步的指导。